AI Agents Building
Enterprise AI Agent Architecture Blueprint (2026): Tools, Memory, Guardrails, and Production Operations
A long-form, research-backed implementation guide for building enterprise AI agent systems with orchestration, retrieval, governance, and measurable reliability.
1) Why Enterprise AI Agents Need a Different Architecture
Many teams start an AI agent initiative by combining a prompt, a model, and a few API calls. That approach can produce a convincing demo quickly, but it usually breaks when exposed to real production variability. Enterprise environments introduce identity boundaries, compliance constraints, latency limits, competing objectives, and changing data quality. A one-loop prompt workflow has almost no control plane for these realities. The result is often inconsistent outputs, ambiguous ownership during failures, and low confidence from operational stakeholders.
A production agent system needs to be treated as an engineered runtime, not just an interface pattern. You need explicit planning behavior, constrained execution rights, deterministic tool contracts, recoverable state, and traceability for every side effect. If the system can create tickets, modify records, or trigger downstream actions, architecture quality becomes a risk management issue, not only a developer productivity topic. This is why the strongest agent teams split concerns into orchestration, tooling, memory, policy, and evaluation layers.
Research and standards guidance point in the same direction. ReAct-style methods showed the value of interleaving reasoning and action for better outcomes on tasks that require external knowledge. Toolformer demonstrated that tool usage can be learned and formalized rather than treated as ad hoc prompt glue. NIST AI RMF emphasizes lifecycle risk governance rather than one-time model selection decisions. OWASP LLM guidance highlights that prompt injection, insecure outputs, and overprivileged integrations can destabilize systems rapidly unless constrained by design.
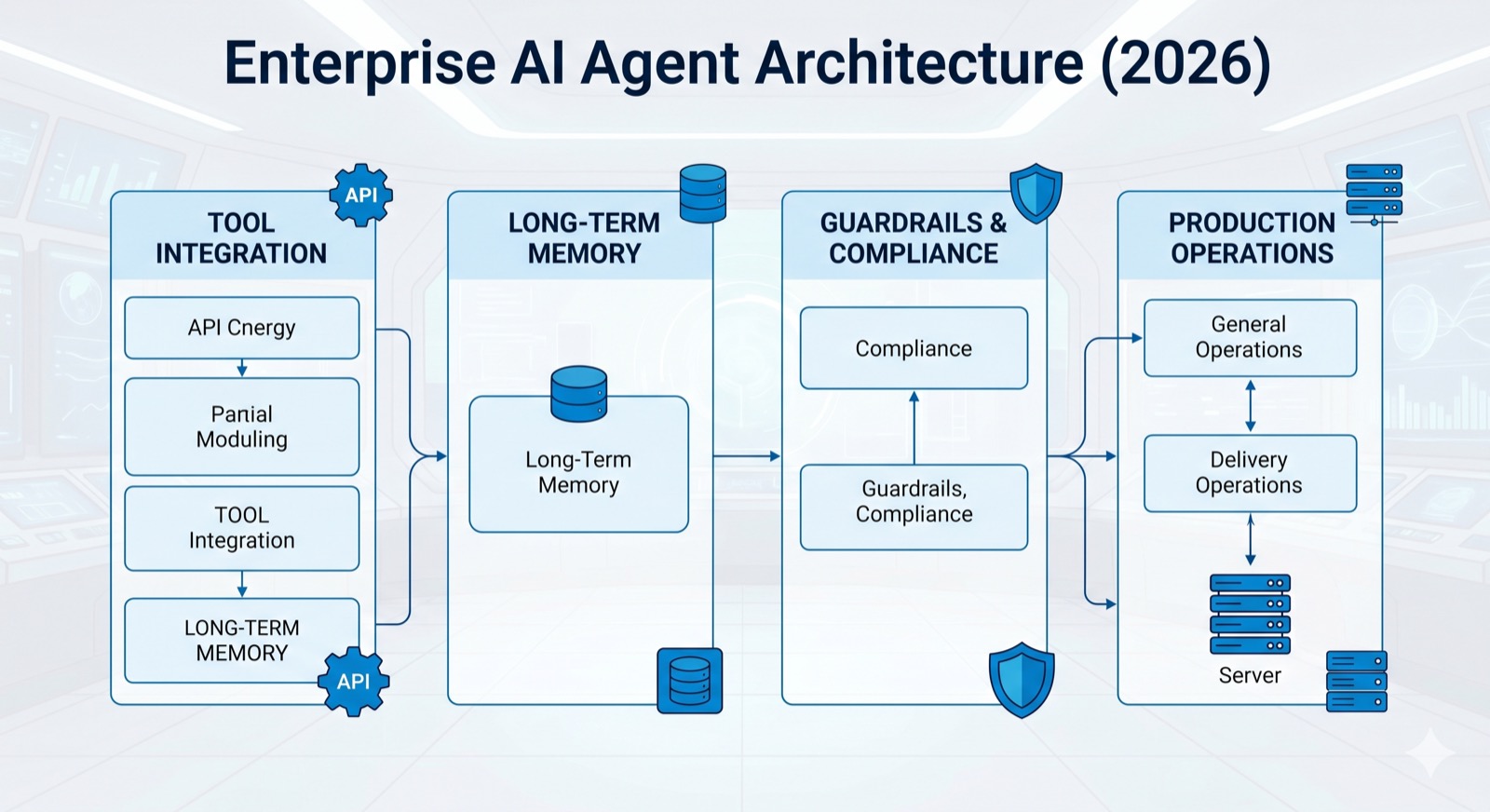
2) The Core Reference Stack for Agentic Systems
A practical enterprise reference stack has six layers. Layer one is the interface layer where requests enter from chat, API, workflow triggers, or contact center events. Layer two is the orchestration layer where task decomposition, planning loops, and routing decisions happen. Layer three is the tool layer containing strict contracts for internal actions. Layer four is the memory and retrieval layer for context persistence and knowledge grounding. Layer five is the policy and safety layer enforcing constraints. Layer six is the observability and evaluation layer that verifies quality over time.
The most common implementation mistake is collapsing all these layers into one prompt template. Doing so makes it difficult to reason about errors because instruction logic, permissions, retrieval behavior, and output formatting are tightly coupled. A better approach is to treat prompts as one control input among many. Externalize policy checks, isolate tool adapters, and keep retrieval choices configurable. That separation lets teams adjust individual failure domains without destabilizing everything else.
In mature environments, each layer has an owner. Product teams often own user intent design and interaction goals. Platform engineering owns orchestration, reliability, and deployment controls. Security governs policy boundaries and audit expectations. Operations and analytics teams own quality metrics and exception workflows. Shared ownership models reduce blind spots, especially when agent behavior influences customer communications or regulated decision pathways.
3) Planning, Reasoning, and Execution Loops
Planning loops should produce bounded, reviewable plans rather than unconstrained chains of action. The orchestrator should ask the model to generate a task plan with explicit assumptions, required tools, expected outputs, and stop conditions. This turns free-form agent behavior into a set of checkpoints. Each checkpoint can be validated before execution. If assumptions are missing or tool access is unavailable, the run can fail safely with an actionable diagnostic rather than continuing into hidden failure.
ReAct-style reasoning and acting remains relevant because it separates “thinking about what to do” from “doing things in the world.” In production, this separation allows policy controls to intercept actions before side effects occur. For example, an agent can reason that it should issue a refund, but refund execution must pass policy checks: user authorization, order validation, escalation requirements, and fraud thresholds. This structure improves reliability and auditability while preserving the productivity benefit of model-guided planning.
Execution loops should also support retries with state awareness. A retry is not a blind rerun. The system should classify failure type first: transient dependency failure, invalid tool arguments, missing data, policy rejection, or model uncertainty. Each class needs a different remediation strategy. Transient API failures may retry automatically. Policy rejections should surface to human operators. Missing data should trigger evidence requests. Model uncertainty should prompt fallback flows. Explicit failure taxonomy improves throughput and trust.
4) Tool Contracts, Function Calling, and Action Safety
Tool use is where enterprise value is unlocked, but it is also where most incidents originate. When an agent can call systems that write data, send messages, or alter workflow state, every tool becomes a high-impact interface. OpenAI function calling guidance and structured output patterns are useful here because they force explicit schemas for inputs and outputs. Schemas reduce ambiguity and make pre-execution validation straightforward. Strong tool contracts are not only for developer ergonomics; they are a safety control.
Each tool should declare scope, required authorization context, data classifications touched, expected side effects, idempotency behavior, and rollback path. For high-risk actions, define a dry-run mode that returns predicted changes without committing them. The orchestrator can use dry-run results to request human approval before final execution. This pattern preserves automation speed for low-risk actions while maintaining governance in sensitive operations.
Keep tool surfaces narrow. It is safer to expose five purpose-specific tools than one unrestricted “database query” tool. Narrow tools let you encode policy at the interface boundary and limit blast radius if prompt injection attempts to redirect behavior. OWASP GenAI guidance repeatedly stresses this principle: minimize privilege, validate parameters, sanitize outputs, and log action decisions with enough context for forensic analysis.
5) Memory Strategy: Working, Episodic, and Durable Context
Agent memory should not be a single monolithic store. A useful model is three memory types. Working memory is run-scoped and ephemeral. Episodic memory stores short-horizon summaries from recent interactions. Durable memory contains validated long-term facts and preferences with retention policies. This separation avoids context overload and limits the risk of stale or conflicting information influencing current decisions.
Reflexion-style ideas can improve iterative performance when applied carefully. The concept of verbal reflection is valuable, but enterprise systems should never accept self-generated reflections directly into durable memory without verification. Reflection output can be stored as candidate insights, then promoted through quality checks or human review. This keeps learning signals useful while preventing accumulation of low-confidence interpretations.
Memory governance is critical for privacy and compliance. Define what can be stored, how long it lives, and which roles can access it. For personal or regulated data, use minimization by default and maintain deletion workflows tied to legal or customer requests. Durable memory should include provenance metadata so teams can determine whether a fact came from a trusted system, model inference, or user-provided text.
6) Retrieval Architecture and Grounded Responses
Retrieval-augmented patterns remain one of the strongest levers for factual quality. The original RAG research highlighted a core limitation of parametric-only systems: they cannot be updated or attributed as cleanly as systems that combine generation with external knowledge access. In practice, this means enterprise agents should treat retrieval as a first-class architectural layer, not a patch added only after hallucination incidents occur.
A robust retrieval stack includes ingestion pipelines, chunking strategy, metadata normalization, embedding/index maintenance, query rewriting, reranking, and citation formatting. Many teams stop at embedding and similarity search, but quality failures often arise from poor document hygiene and retrieval relevance tuning. Evaluate retrieval independently from generation so you can isolate where errors originate: index quality, query logic, or model interpretation.
Grounding also requires source trust tiers. Not all knowledge sources should be treated equally. Build allowlists for authoritative systems and apply confidence scoring for less trusted inputs. If retrieved evidence conflicts, the agent should either request clarification or surface uncertainty explicitly. This behavior is preferable to forcing a single confident answer when evidence quality is low.
7) Orchestration Patterns: Single Agent, Multi-Agent, and Hybrid
Single-agent systems are often enough for early production use cases when tasks are linear and tool count is low. They are easier to observe and cheaper to operate. However, as workflow complexity grows, one agent can become a bottleneck for reasoning quality and latency. At that point, multi-agent decomposition can improve maintainability by separating planning, execution, validation, and reporting responsibilities.
A common production pattern is planner-executor-reviewer. The planner defines steps and dependencies, the executor performs tool actions, and the reviewer checks output quality against policy and task criteria. This structure creates built-in quality gates and makes failures easier to classify. It also supports selective model allocation: strong reasoning models for planning, lower-cost models for deterministic transformations, and rule-based validators for safety-critical checks.
Hybrid orchestration blends model-driven routing with deterministic workflow engines. Deterministic orchestration should own critical branching logic, deadlines, and retries, while model reasoning contributes interpretation and strategy. This avoids the fragility of pure prompt orchestration and preserves operational predictability. It also aligns with enterprise change management because deterministic workflows are easier to audit and test.
8) Security Threat Model for Agentic Applications
Security architecture should begin with an agent-specific threat model, not a generic web app checklist. OWASP LLM risk categories are a useful starting lens: prompt injection, insecure output handling, excessive agency, sensitive information disclosure, and supply chain issues. These risks become more severe when the system can take actions across business systems. You must model attackers at both the prompt layer and the integration layer.
Prompt injection defense cannot rely on one filter. Use layered controls: instruction hierarchy, input normalization, source trust scoring, tool allowlists, parameter validation, output policy checks, and runtime anomaly detection. High-risk instructions should require explicit confirmation or human review. Treat retrieved content and external web data as untrusted by default, even when sources appear reputable.
Credential and secret handling deserves special attention in agent systems. Never expose broad credentials to the model runtime. Use short-lived, scoped tokens brokered by a secure execution layer. Maintain strict separation between model context and secret stores. Log only redacted execution traces. These controls reduce lateral movement risk if prompt compromise occurs.
9) Governance Framework: Applying NIST AI RMF to Delivery
NIST AI RMF provides a practical structure for moving from experimentation to accountable production operations. Its four functions, Govern, Map, Measure, and Manage, map naturally to agent lifecycle activities. Govern defines roles, accountability, and policy expectations. Map identifies context, stakeholders, and impact scenarios. Measure evaluates risks and quality signals. Manage prioritizes mitigations and operational actions.
In delivery practice, Govern means creating clear decision rights for product, engineering, security, and legal teams. Map means documenting user journeys, affected systems, and failure consequences. Measure means running evals, red-team exercises, and operational KPIs continuously. Manage means implementing incident playbooks, rollback paths, and iterative mitigation plans. Teams that explicitly map backlog items to these four functions usually progress faster with fewer production surprises.
The key insight is that governance should not be a late-stage review gate. It should be embedded into architecture decisions from the first production candidate. This reduces rework and strengthens stakeholder trust because controls are visible as part of the build, not retrofitted under pressure.
10) Evaluation Design: Reliability Is a Product Requirement
Agent quality cannot be inferred from anecdotal demos. Reliability emerges from disciplined evaluation across representative tasks, adversarial inputs, and operational edge cases. Build a benchmark dataset that includes routine tasks, ambiguous requests, malformed inputs, and policy-sensitive scenarios. Score not just final answer quality, but process quality: correct tool selection, valid parameters, and policy compliance.
OpenAI eval workflows and general evaluation practice support this model by separating test definition from prompt iteration. Teams should track pass rates by task class, latency distributions, retry rates, and human override frequency. Changes to prompts, tools, model versions, or retrieval pipelines should trigger controlled eval runs before broad release. This turns architecture evolution into measurable engineering change, not intuition-driven trial and error.
Include negative tests intentionally. Attack-oriented prompts, conflicting evidence, and boundary condition tasks reveal fragility faster than standard happy-path samples. Record failure categories and establish service-level objectives for quality. For example: tool argument validity above a target threshold, policy violation rate below a threshold, and escalation accuracy within a defined range.
11) Human-in-the-Loop Design for High-Stakes Workflows
Automation strategy should be risk-tiered. Low-risk repetitive tasks can run with minimal supervision. Medium-risk tasks should require sampled review and exception monitoring. High-risk tasks should require explicit human approval before side effects. OpenAI safety guidance also emphasizes human oversight for high-stakes decisions. This is not a limitation of the technology; it is an operational control that protects both users and organizations.
Human-in-the-loop design works best when reviewers receive structured context, not raw transcripts. Present task intent, evidence used, tool actions proposed, confidence rationale, and policy checks passed. This shortens review time and improves decision consistency. If reviewers need to reconstruct context manually every time, throughput collapses and teams disable oversight under delivery pressure.
Review data should feed improvement loops. Track why humans override agent recommendations, then convert those patterns into policy updates, better retrieval indexing, or tool contract improvements. Over time, this decreases manual burden while increasing reliability. HITL is most valuable when it is integrated into system learning, not treated as static manual QA.
12) Observability, Tracing, and Incident Response
Agent observability should capture full execution lineage: user intent, planner output, selected tools, tool inputs, policy checks, action results, and final response. Without this chain, teams cannot diagnose whether failures came from model reasoning, retrieval quality, tool reliability, or policy design. Logs should be structured and queryable by run ID, customer segment, workflow type, and failure class.
Define incident categories before launch. For example: unsafe action attempt, policy bypass, incorrect high-impact decision, runaway loop, integration timeout cascade, or retrieval contamination. Each category needs triage procedures, ownership, communication templates, and rollback actions. Incident preparedness is what separates enterprise agent programs from pilot projects.
Post-incident reviews should produce concrete artifacts: failing test cases added to eval suites, updated policy rules, modified tool permissions, and architectural remediation tasks. Avoid root-cause statements that stop at “model hallucinated.” Hallucination is usually an outcome of upstream architectural or governance weakness.
13) Data Architecture and Knowledge Ops
Agents are only as reliable as the systems they can query and the data they can trust. Knowledge operations should include ownership for ingestion quality, schema consistency, versioning, and retirement of stale documents. Teams often underestimate the operational burden of knowledge hygiene. In practice, this is one of the biggest determinants of long-term agent quality.
Define canonical knowledge sources for each business domain. For customer policy questions, a policy repository may be canonical. For incident diagnosis, runbook systems may be canonical. For billing and account status, transactional systems are canonical. Retrieval should prioritize canonical sources first, then supplementary sources with lower trust weighting.
Introduce freshness controls where decisions depend on current state. If a source has delayed synchronization, the agent should expose that limitation rather than presenting stale facts as current truth. Metadata timestamps and confidence annotations improve operator trust and reduce decision risk.
14) Performance Engineering: Latency, Cost, and Throughput
Enterprise agent systems must meet practical service targets. Even if answer quality is strong, poor latency or unpredictable cost can block adoption. Performance engineering should begin with workload segmentation. Some workflows require deep reasoning and tolerate longer turnaround. Others demand near-real-time responses and should use narrower context and deterministic transformations.
Use routing strategies that match task complexity to model capability and tool depth. Not every step needs the highest-intelligence model. Planner stages may justify stronger reasoning, while extraction or formatting stages can run on lower-cost paths with structured outputs. This architecture reduces cost without sacrificing quality where it matters.
Measure end-to-end latency components independently: retrieval time, model inference time, tool call time, policy check time, and approval wait time. Bottleneck visibility enables targeted optimization. Without decomposition, teams over-optimize prompts while ignoring integration delays that dominate user-perceived performance.
15) Compliance and Audit Readiness
Compliance readiness for agentic systems depends on evidence quality. Auditors and internal risk teams need to see who authorized what, which policy applied, which data was accessed, and how decisions were produced. This requires durable traces, not temporary logs that disappear after short retention windows. Design retention and redaction strategy early so you can satisfy both privacy requirements and accountability needs.
Policy-as-code helps align engineering and compliance objectives. Convert critical decision rules into explicit checks in the orchestration layer. Examples include jurisdictional constraints, approval thresholds, communication rules, and data residency restrictions. When policy logic is encoded programmatically, it becomes testable and versioned, reducing ambiguity during reviews.
Create compliance runbooks for common regulator or customer requests: decision provenance reports, deletion requests, incident disclosure procedures, and model change documentation. Operational preparedness lowers risk and shortens response times under scrutiny.
16) Contact Centre and Operations Use Cases That Deliver Early Value
For most organizations, contact centre and operations workflows are ideal early targets because they contain repetitive tasks, measurable KPIs, and existing process documentation. Good initial use cases include ticket summarization, intent routing, response drafting, SLA risk flagging, and quality-assurance pre-scoring. These use cases create fast value while preserving human oversight.
As maturity grows, agents can support more complex workflows such as cross-system case orchestration, follow-up automation, and policy-constrained remediation actions. The transition from assistive to semi-autonomous behavior should be deliberate. Each step should be backed by benchmark performance, policy coverage, and incident readiness.
Success metrics should be balanced: handle time, first-contact resolution, escalation accuracy, quality score stability, and customer satisfaction. Optimizing only one metric often creates hidden regressions. For example, reducing handle time while increasing repeat contacts is not a win.
17) Implementation Roadmap for Ontario and Canadian Teams
A realistic roadmap starts with a 30-day foundation sprint. Identify two to three high-value workflows, map system integrations, define risk tiers, and implement a baseline orchestrator with strict tool schemas. Launch a controlled pilot in one business unit with clear KPI ownership. Keep scope narrow enough to learn quickly without creating governance debt.
In days 30 to 90, expand from pilot to production readiness. Add retrieval quality monitoring, policy enforcement, eval automation, and incident runbooks. Introduce service-level objectives for reliability and latency. Formalize change control for prompts, tools, and model versions. If human reviewers are involved, provide structured review interfaces and training.
From day 90 onward, scale selectively. Add new workflows only when observability and policy coverage are proven. Use shared architecture patterns to avoid fragmented one-off agent implementations across departments. This portfolio approach is where many organizations unlock compounding value while controlling risk.
18) Common Failure Patterns and How to Avoid Them
Failure pattern one is over-permissioned tool access. Teams give agents broad API keys to move fast, then struggle to contain behavior. Prevent this by defaulting to least privilege, short-lived credentials, and explicit action allowlists. Failure pattern two is weak retrieval governance. If source trust and freshness are unmanaged, the system can confidently produce outdated or conflicting guidance.
Failure pattern three is missing eval discipline. Prompt changes, model upgrades, and new tools are deployed without regression tests. Reliability drifts slowly until a major incident exposes the weakness. Build mandatory eval gates for high-impact workflows and track quality trends over time. Failure pattern four is no escalation design. When uncertain, the agent still acts instead of requesting human intervention.
Failure pattern five is architecture lock-in around one vendor-specific feature set without abstraction boundaries. Keep interfaces modular so you can evolve model providers, retrieval systems, and policy engines as requirements change. This preserves strategic flexibility and reduces long-term operational risk.
19) A Practical Blueprint You Can Execute This Quarter
Start by defining one business objective per workflow. Example objectives include reducing support backlog, accelerating case resolution, or improving internal knowledge retrieval time. Tie each objective to measurable KPIs and operational constraints. Then create a workflow contract: input channels, tool dependencies, policy boundaries, and escalation rules. This contract becomes your build specification.
Next, implement a minimal but production-shaped runtime. Include orchestrator, schema-based tool calling, retrieval with source metadata, policy checks, and structured logging. Avoid premature complexity but do not skip controls. Teams that defer controls rarely return to them under growth pressure. Validate each workflow with representative tests plus adversarial scenarios before enabling broad user traffic.
Finally, institutionalize ownership. Assign product ownership for outcome quality, platform ownership for reliability and deployment, and security ownership for policy and threat controls. Build weekly review loops for metrics and incidents. This operating cadence is what converts agent experiments into durable enterprise capability.
20) Final Perspective: Build for Trust, Not Only Automation
The strongest enterprise agent programs do not optimize for maximum autonomy on day one. They optimize for trustable autonomy over time. That means explicit architecture boundaries, measurable quality, strong governance, and transparent operations. When users and stakeholders can understand why the system acted, they are more willing to expand its scope.
Research, standards, and field implementation converge on one principle: capability without control is fragile. ReAct and tool-use research highlight how agents can become more effective through structured interaction with external systems. NIST and OWASP guidance emphasize that effectiveness must be paired with risk management and secure-by-design practices. OpenAI and broader platform guidance shows how structured outputs, function calling, moderation, and evals can operationalize these controls.
For teams in Ontario and across Canada, this is an opportunity to build a real advantage. Organizations that treat agent architecture as disciplined engineering will outperform those relying on prompt-only shortcuts. The near-term winners will be teams that ship useful automation while keeping humans, policy, and evidence in the loop. That combination creates systems that are not only impressive in demos, but dependable in production.
Research sources
- ReAct: Synergizing Reasoning and Acting in Language Models (arXiv)
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (arXiv)
- Toolformer: Language Models Can Teach Themselves to Use Tools (arXiv)
- Reflexion: Language Agents with Verbal Reinforcement Learning (arXiv)
- NIST AI RMF Playbook
- OWASP Top 10 for LLM Applications 2025
- OpenAI Function Calling Guide
- OpenAI Structured Outputs Guide
- OpenAI Evals Guide
- OpenAI Safety Best Practices
- OpenAI Moderation Guide
Where we can help
- Assess whether your current workflows are suitable for agentic automation and define the right risk tier for each flow.
- Design a production architecture for tools, memory, retrieval, and policy controls that matches your compliance requirements.
- Implement evaluation pipelines and operational guardrails so reliability improves with each release cycle.